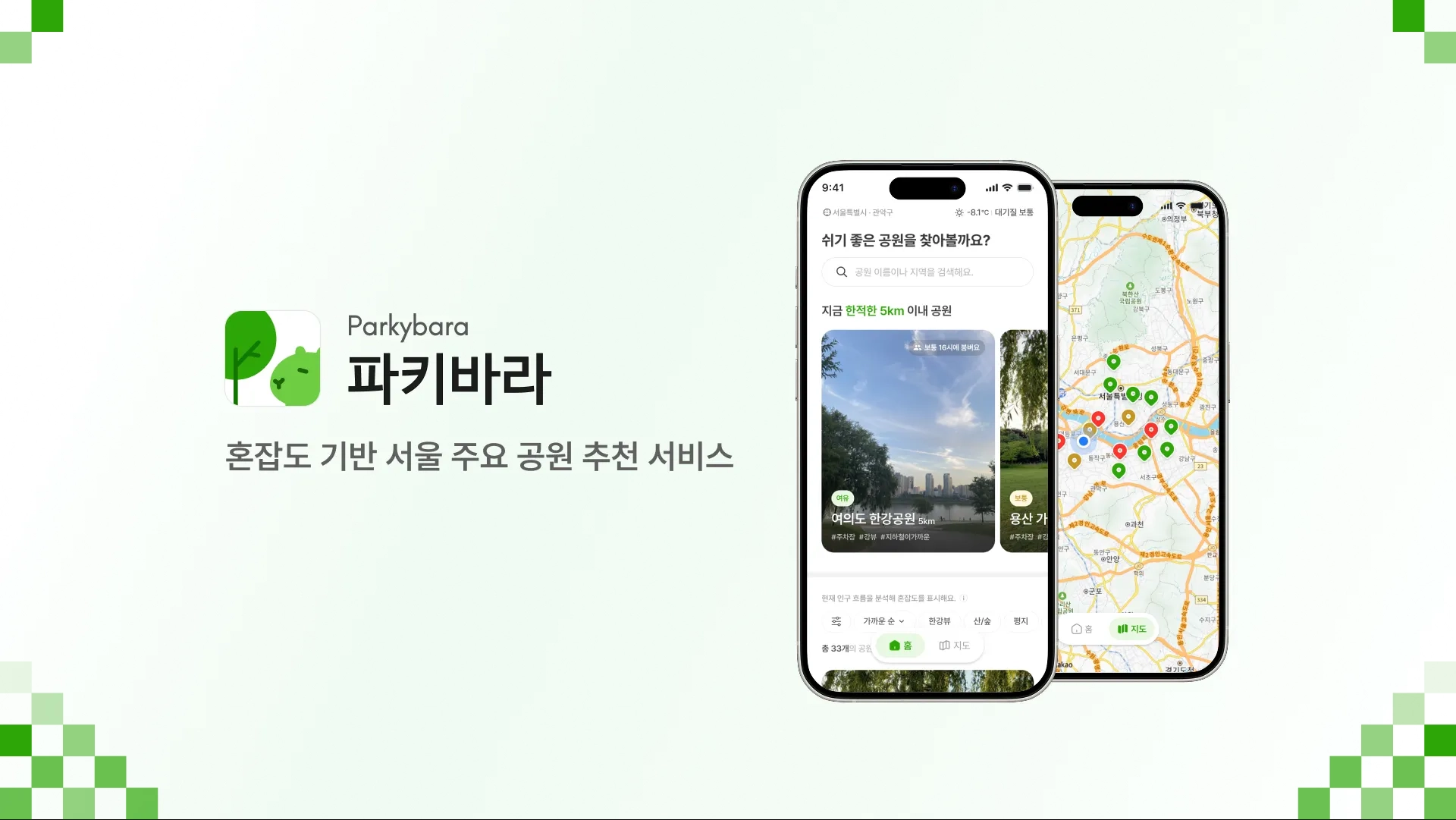
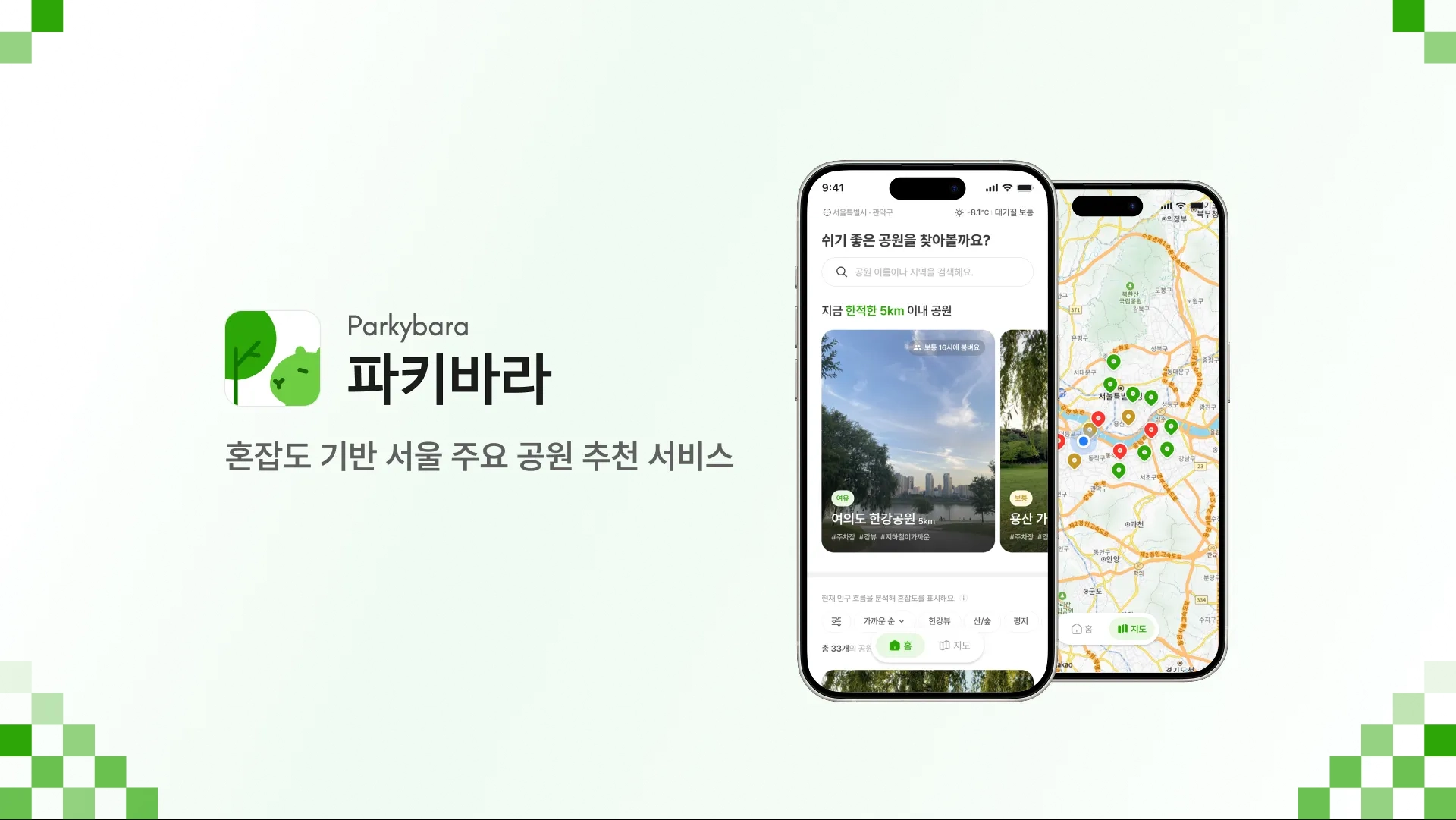
1. 서비스 소개
공원 방문 전 다음과 같은 질문을 고민해보신 적이 있으신가요?
“지금 공원 가면 사람이 너무 많지는 않을까?”
“어느 공원이 가장 덜 붐빌까?”
“이번주 주말은 사람이 얼마나 있으려나?”
이런 고민을 해보셨다면 ‘파키바라’를 사용해보세요!!
저희는 휴식을 위해 공원을 방문하는 분들께 서울시 공공데이터를 활용한 혼잡도 정보를 통해 공원 정보를 큐레이션 해주는 공원 추천 서비스를 제공하고 있어요
2. 서비스 배경
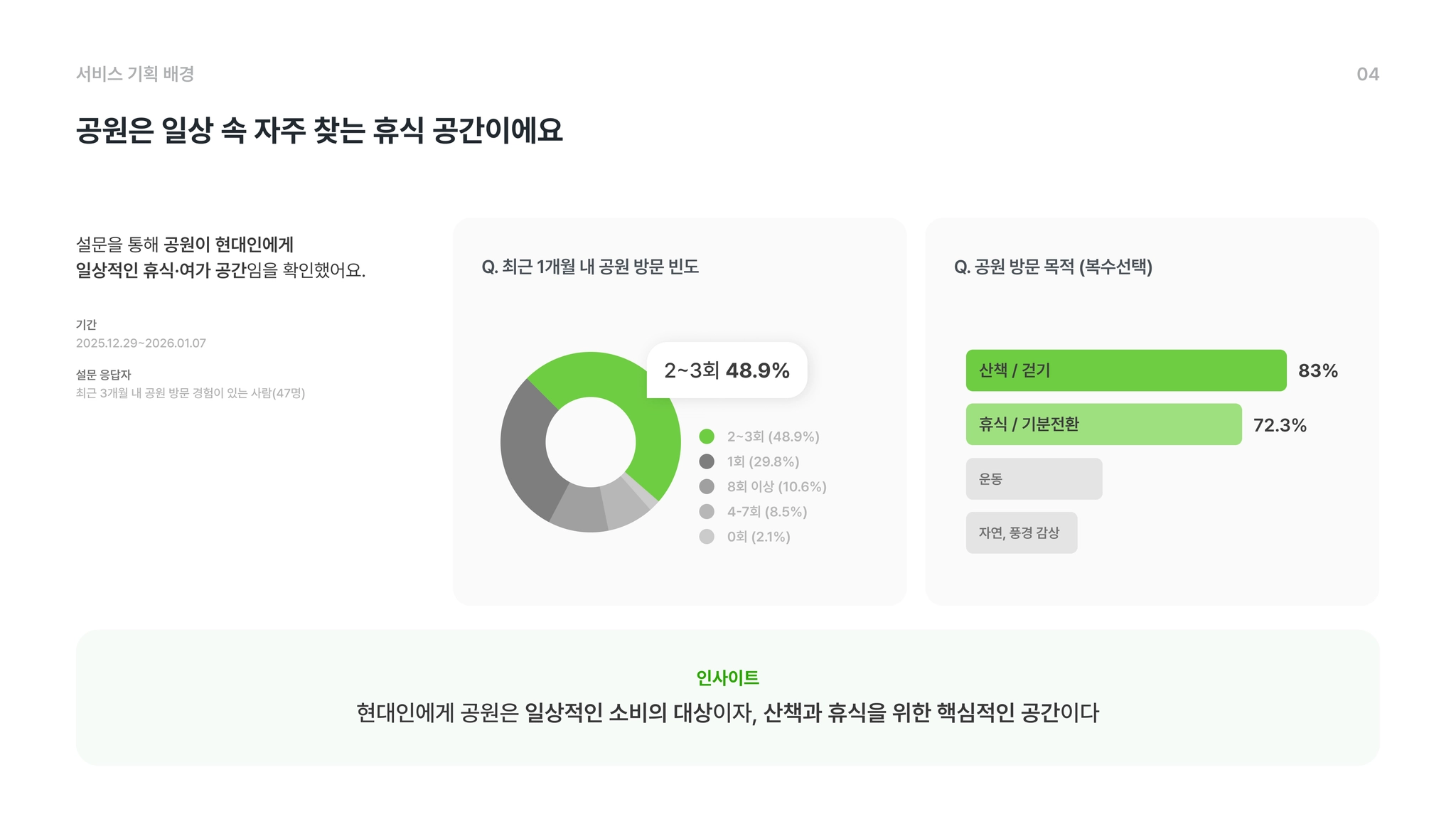
바쁜 일상 속에서 현대인들에게 '공원'은 단순한 녹지 공간을 넘어 정서적 회복과 휴식을 위한 필수적인 장소로 자리 잡았음을 리서치와 자체 설문조사를 통해서 확인 할 수 있었습니다.
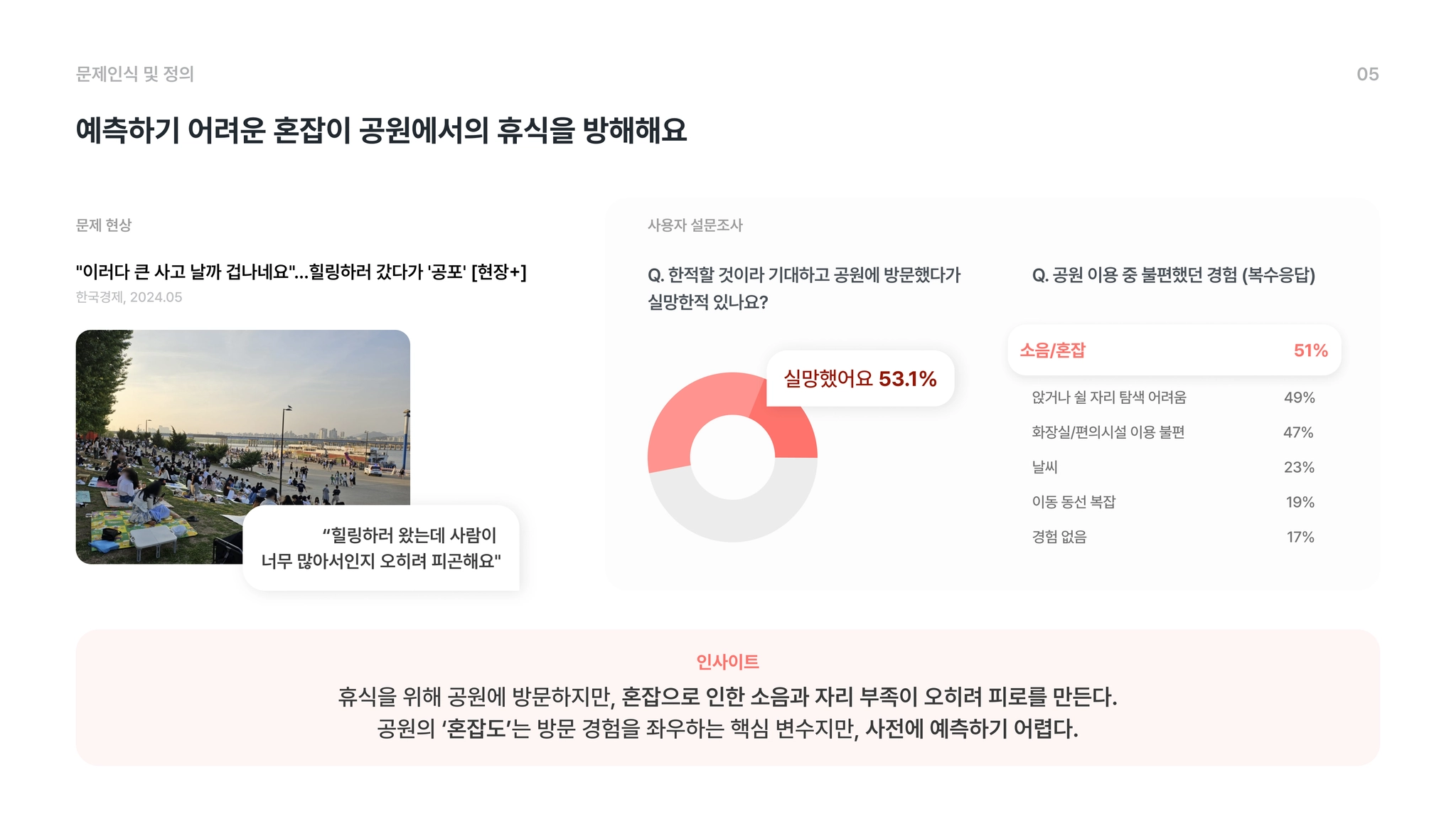
하지만 역설적이게도 휴식을 위해 찾은 공원에서 우리는 또 다른 스트레스를 마주하곤 합니다.
실제로 저희 조사에 따르면 적할 것이라 기대하고 공원을 방문했다가 실망한 경험이 53.1%, 공원이용 중 불편 경험으로 소음/혼잡이 51%로 상당히 높은 수치를 기록하였습니다.
방문하게 된 공원이 발 디딜 틈 없이 인파로 북적이거나, 자리를 찾지 못해 시간을 허비하는 경험은 누구나 한 번쯤 겪어보았을 것입니다.
실제로 저희가 진행한 조사에서도
•
한적할 것이라 기대하고 공원에 방문했다가 실망한 경험 : 53.1%,
•
공원 이용중 가장 불편했던 경험으로 소음/혼잡 : 51%
등의 결과에 높은 수치를 기록하였습니다. 이를 통해 저희는 공원의 ‘혼잡도’에 집중하였습니다.
3. 가설 설정 및 검증

저희는 공원 방문객에게 혼잡도 정보를 제공함으로서 불편 사항을 해결 하고자 하였고 3가지 가설을 설정하였습니다.
•
가설 1: 공원 실시간 혼잡도를 시각화하여 제공한다면 혼잡도 예측을 위한 탐색 행위가 60%이상 감소할 것이다.
•
가설 2: 혼잡도가 낮은 대체 공원 추천해준다면 사용자의 30%는 방문 장소를 변경 할 것이다.
•
가설 3: 혼잡도 예측 정보를 제공한다면 사용자의 30%는 혼잡도가 상대적으로 낮은 시간대로 방문시간을 변경할 것이다.
설문을 통해 각 가설을 검증하였고 저희 서비스의 가능성을 확인할 수 있었습니다.
3-1. 인터뷰 인사이트
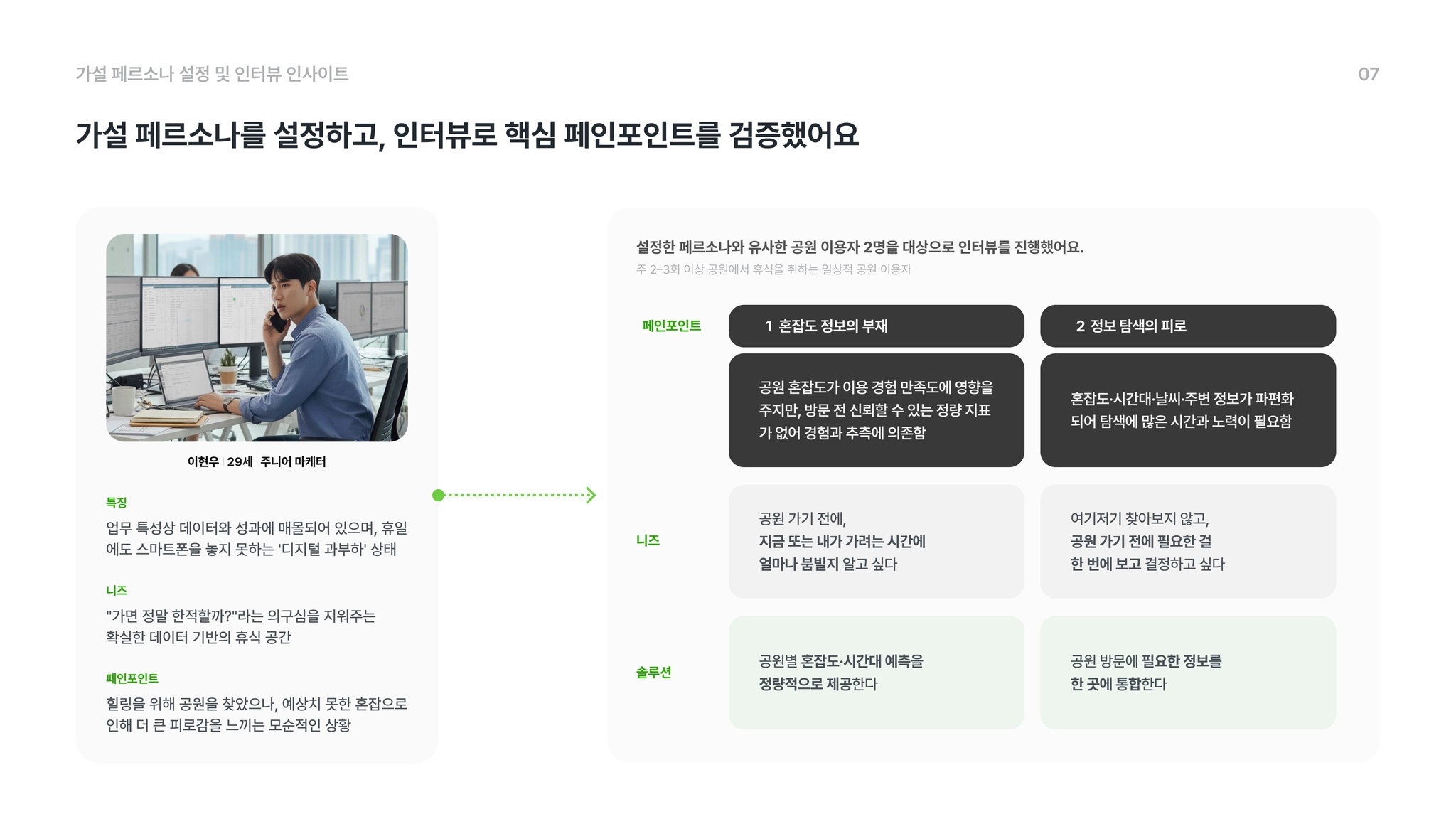
"휴식을 원하지만, 휴식을 위해 '탐색'하는 비용은 너무나 큽니다."
기존의 지도 서비스들은 길 찾기나 장소의 위치 정보를 제공하는 데는 탁월하지만, '지금 이 순간 그 장소의 상태'를 알려주지는 못합니다.
저희는 페르소나를 설정하고 유사한 공원 방문객들과 인터뷰를 진행하였습니다. 각 공원 방문객들은 다음과 같은 Pain Point를 겪고 있었습니다.
•
정보의 파편화: 혼잡도, 공원정보, 날씨, 대중교통, 주차 정보가 각기 다른 플랫폼에 흩어져 있어 방문 전 종합적인 판단을 내리기 어렵습니다.
•
장소 선정의 불확실성: 직접 가보기 전까지는 해당 공원이 얼마나 붐비는지 알 수 없으며, 실패했을 때의 플랜 B(대체지)를 찾는 것도 막막합니다.
•
탐색 비용의 발생: 휴식을 위해 정보를 검색하는 과정 자체가 또 다른 업무처럼 느껴지는 '정보 과부하' 상태에 놓여 있습니다.
4. 핵심 사용자 및 사용 시나리오

인터뷰를 통해 발견한 사용자들의 PainPoint를 바탕으로, 실제 서비스 설계에서 집중할 핵심 사용자를 재정의하고 사용자 경험 시나리오를 수립하였습니다.
4-1. 핵심 사용자 (Target User)
"일상 속에서 가볍게 공원을 찾고, 지금 방문해도 괜찮은지를 빠르게 판단하고 싶은 사용자"
단순히 위치를 찾는 것을 넘어, 실시간 데이터를 통해 '성공적인 휴식'의 확률을 높이고자 하는 도심 생활자를 타겟으로 설정했습니다.
(서울 내 공원으로 MVP 범위 한정: 서울 공공 데이터를 활용해 혼잡도 기반 공원 추천이 사용자 행동 변화에 기여하는지 검증합니다.)
4-2. 핵심 사용 시나리오 (User Scenario)
사용자가 '파키바라'를 통해 문제를 해결하고 한적한 휴식을 얻게 되는 4단계 과정입니다.
•
STEP 01. 서비스 방문: 일상 중 잠깐 산책하며 쉬고 싶을 때, 고민 없이 서비스를 방문합니다.
•
STEP 02. 주변 공원 탐색: 현재 위치를 기반으로 주변의 한적한 공원을 지도와 리스트를 통해 즉시 추천받습니다.
•
STEP 03. 실시간 의사결정: 혼잡도 예측 정보(차트 및 가이드 메시지)를 확인하고, 지금 바로 갈지 아니면 시간을 늦출지 판단합니다.
•
STEP 04. 최적의 장소 이동: 데이터로 검증된 '덜 붐비는 공원'을 선택하여 스트레스 없는 휴식을 즐기러 이동합니다.
5. 핵심 기능 요약
"데이터로 설계한 한적한 휴식 경험"
‘파키바라’는 서울시의 실시간 공공데이터를 기반으로 '혼잡도'라는 직관적인 지표를 제공하여 사용자들의 탐색 비용을 획기적으로 낮추고자 하였습니다.
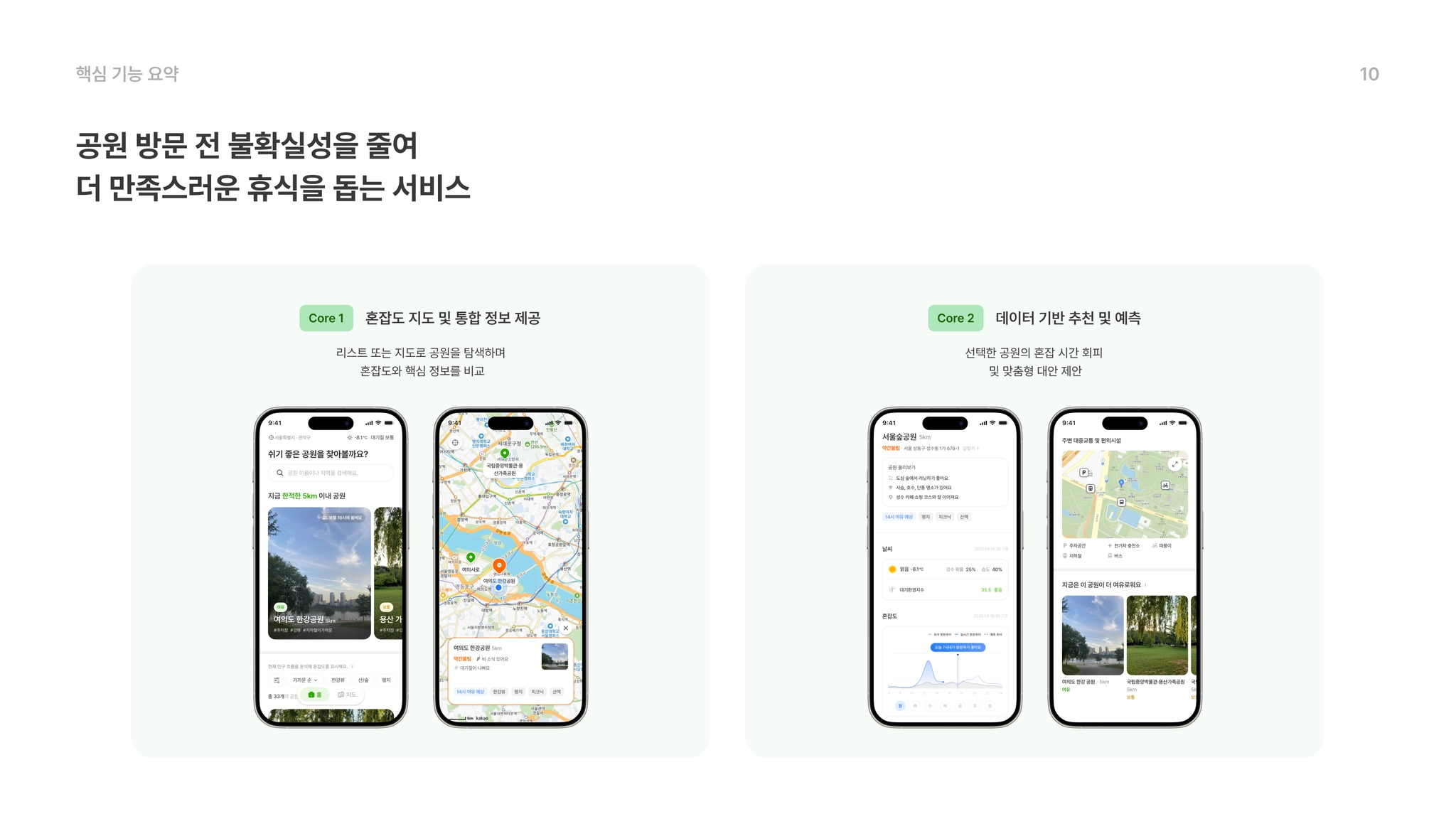
•
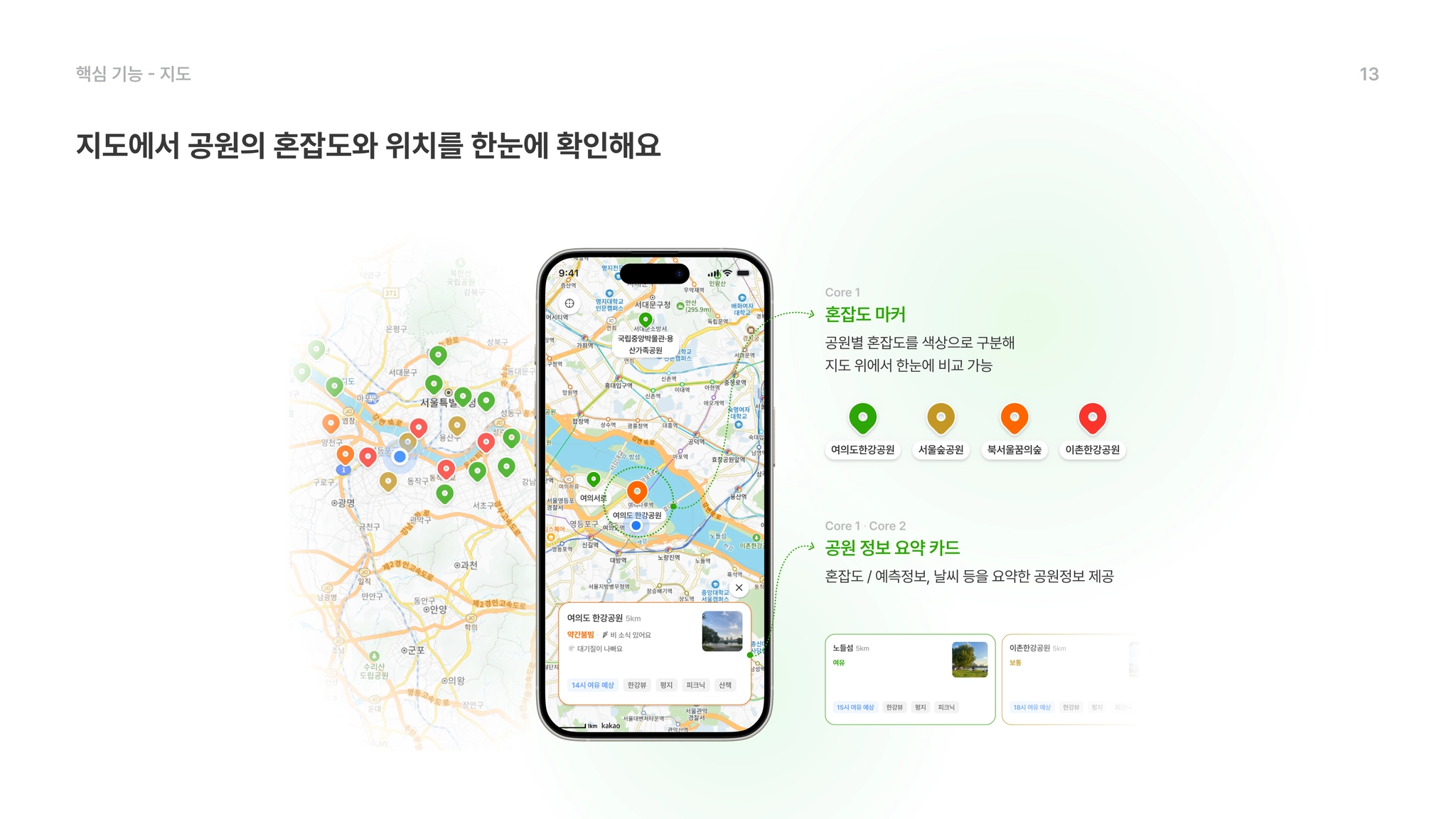
Core 1 : 혼잡도 지도 및 통합 정보 제공
리스트 또는 지도로 공원을 탐색하며 혼잡도와 핵심 정보를 비교한다
◦
실시간 혼잡도 시각화 : 서울시 공공데이터에서 제공하는 혼잡도 데이터를 기반으로 서울시 내 주요 공원의 상태를 4단계로 시각화하여 가장 여유로운 공원을 한눈에 파악합니다.
◦
환경 종합 대시보드: 공원 설명미세먼지, 날씨, 주차 정보, 따릉이 거치소 등 휴식에 필요한 모든 환경 정보를 단 하나의 화면에 담았습니다.
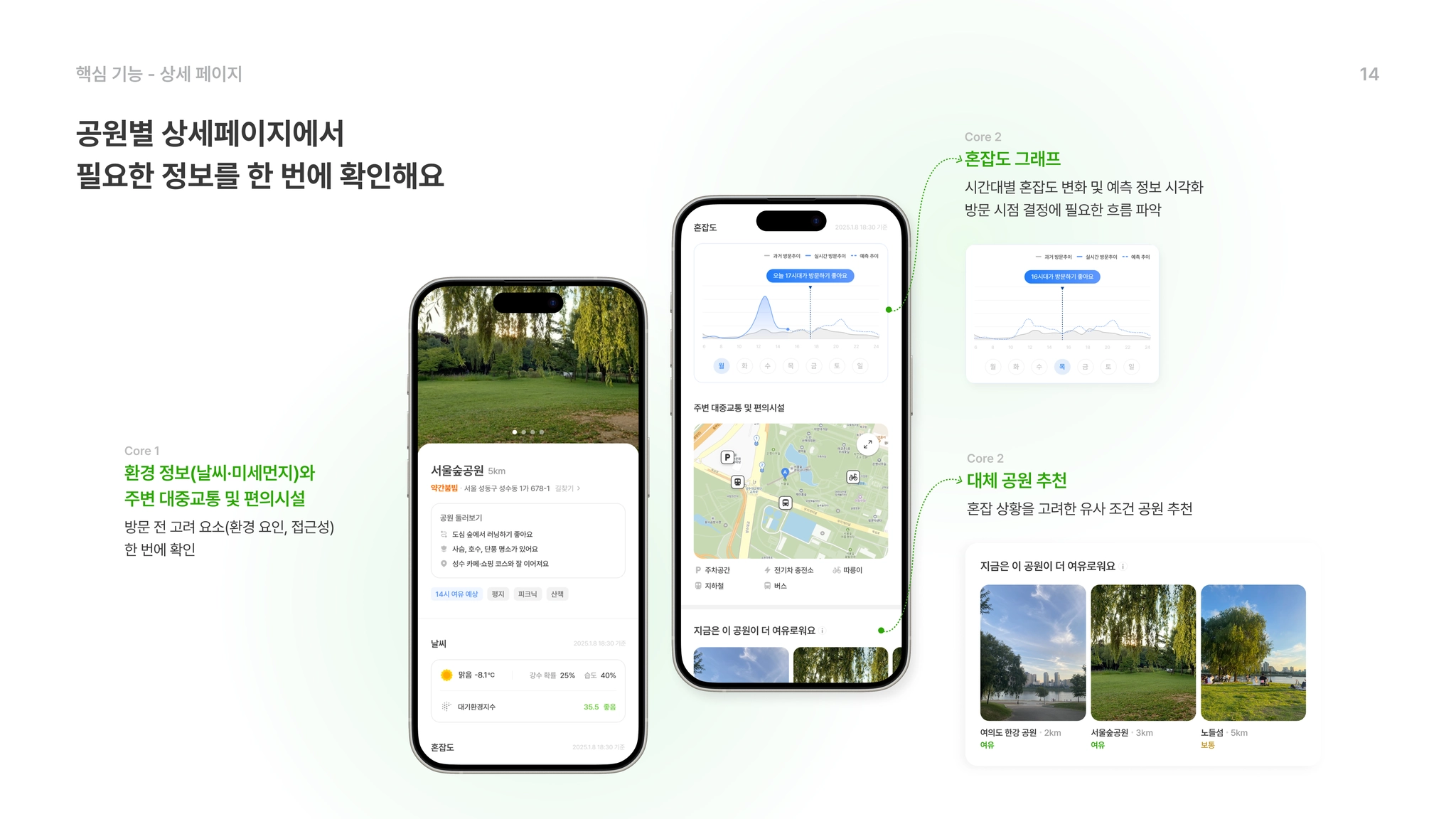
•
Core 2 : 데이터 기반 추천 및 예측
선택한 공원의 혼잡 시간을 예측하고 맞춤형 대체지를 제안한다
◦
데이터 기반 맞춤 추천: 홈 화면에서 또는 방문하고자 하는 공원이 붐빌 경우, 거리와 혼잡도를 계산하여 최적의 대체지(Plan B)를 즉시 제안합니다.
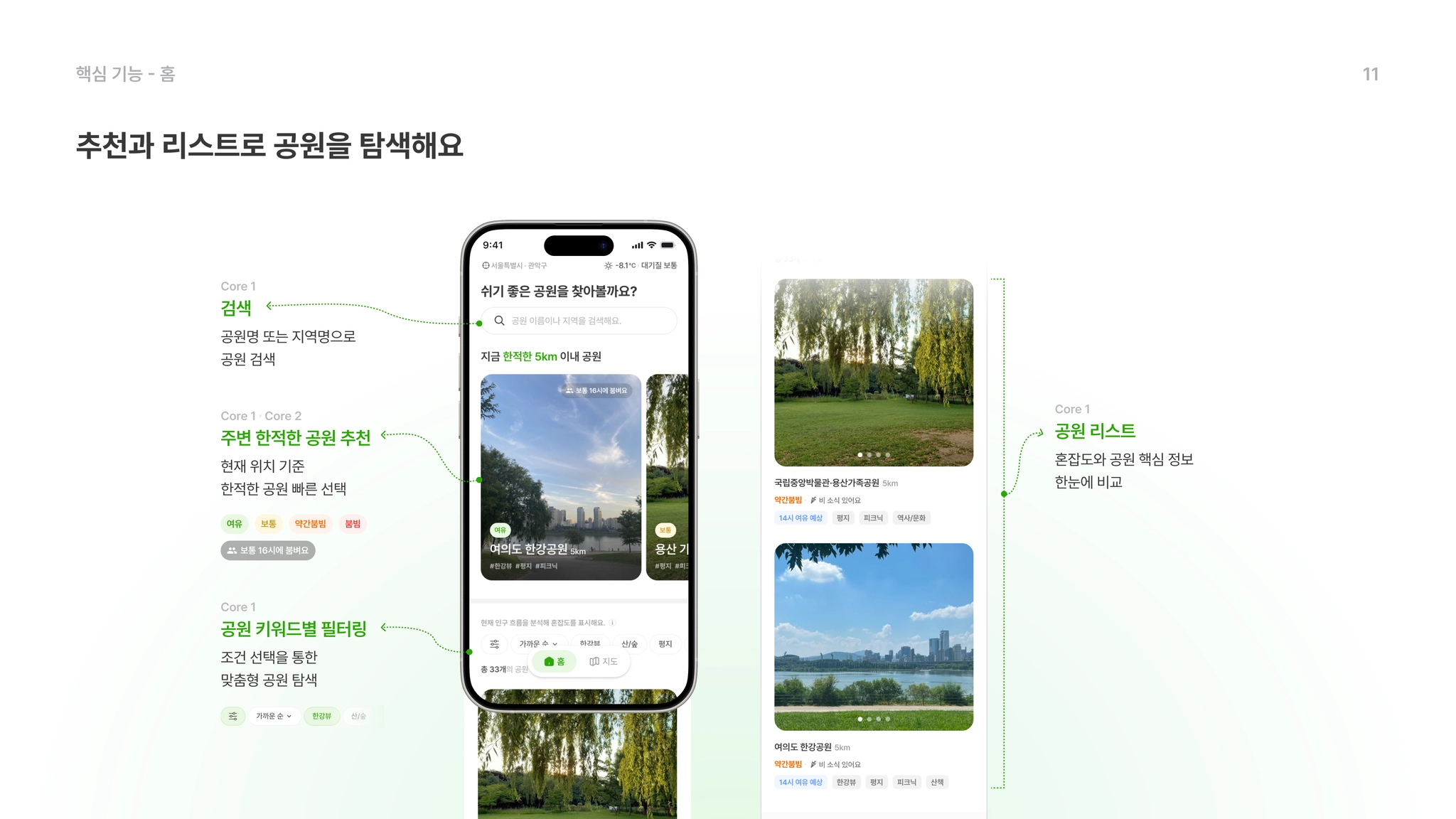
5-1. 페이지별 핵심 기능 소개
5-2. 시연 영상
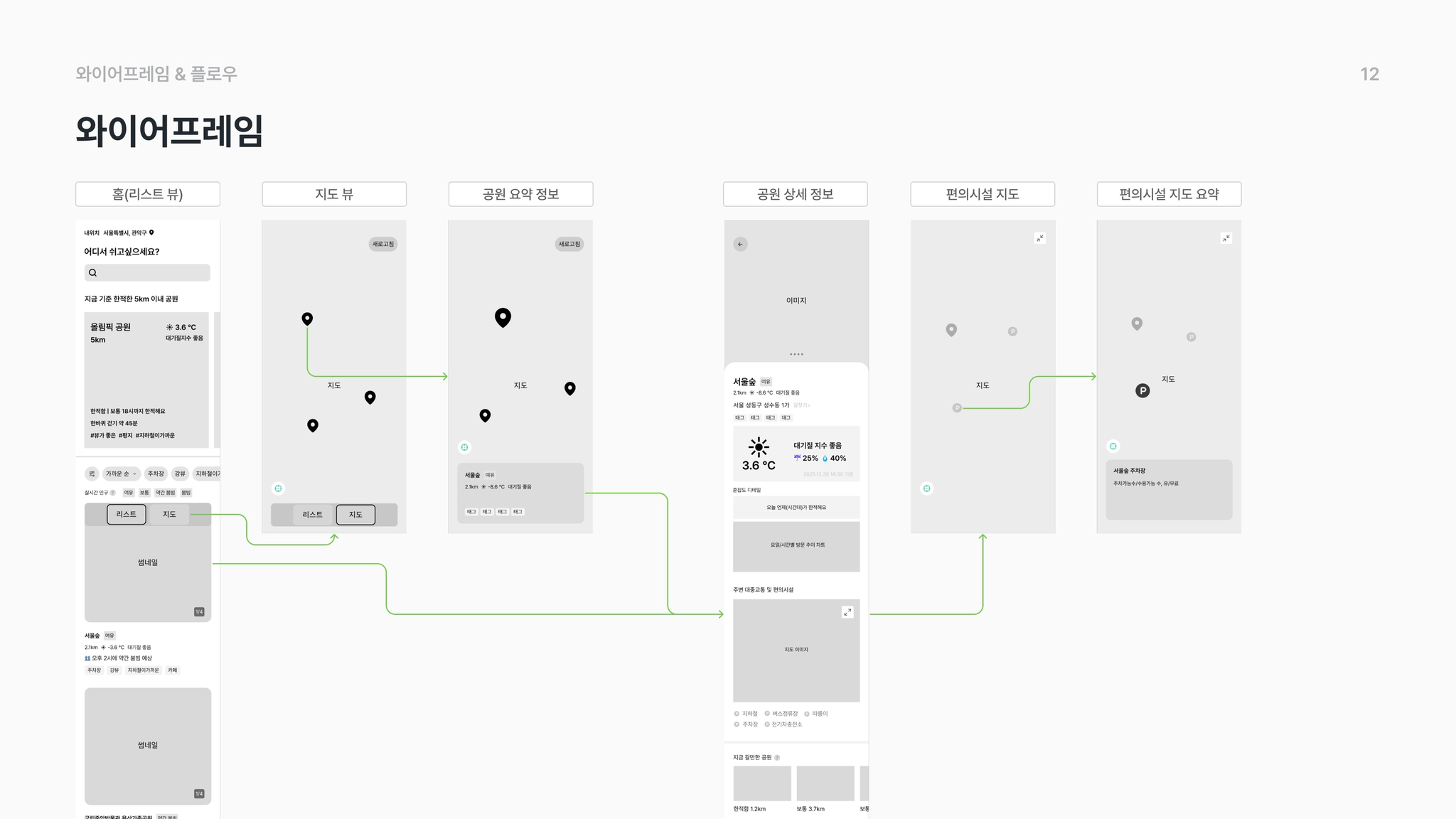
6. 와이어프레임
7. 시스템 아키텍처 및 구현전략
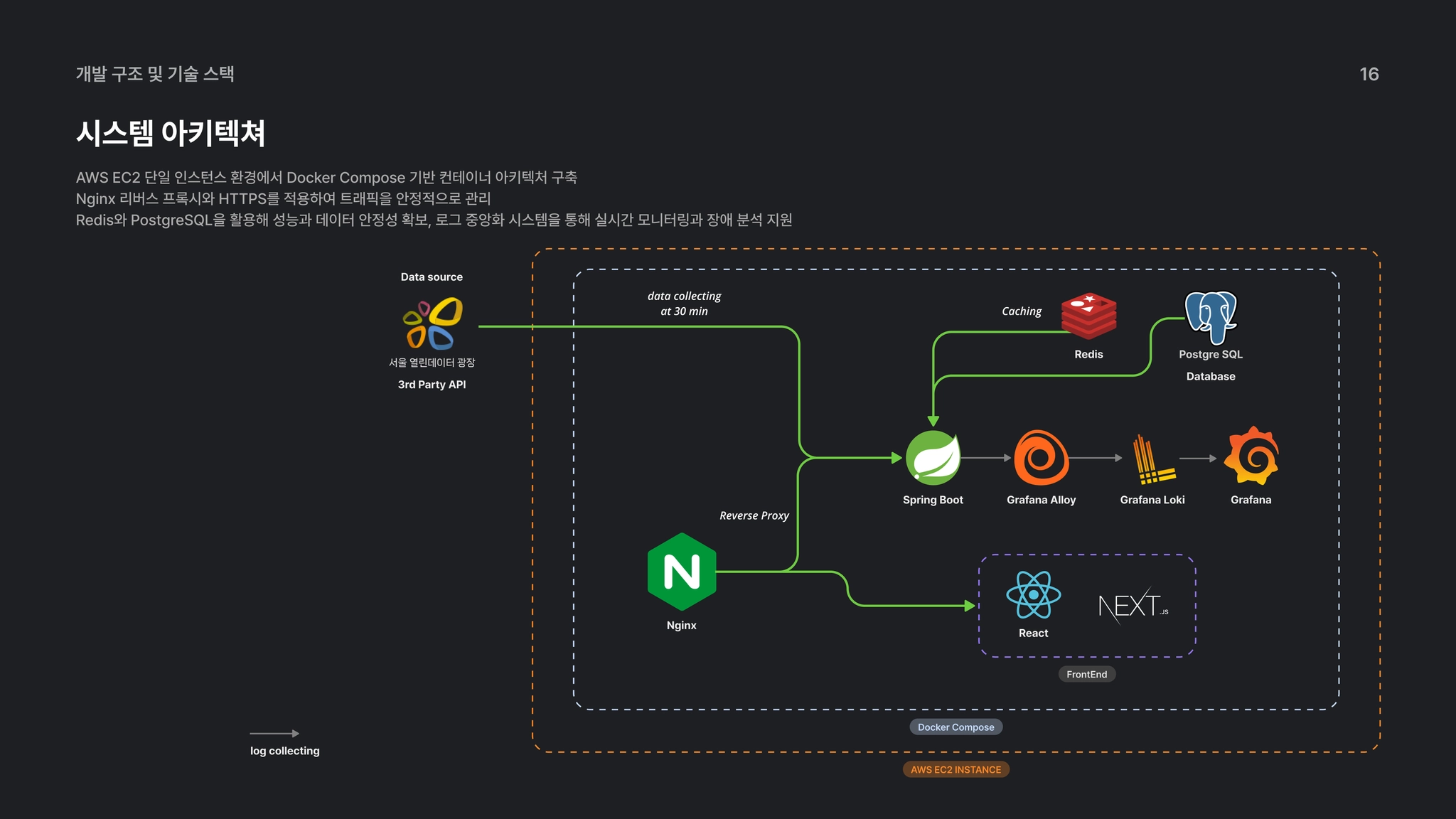
본 프로젝트는 서비스 운영의 안정성과 배포 자동화를 극대화하기 위해 AWS EC2기반의 인프라와 Docker Compose 중심의 컨테이너 아키텍처를 채택하였습니다.
7-1. 시스템 아키텍처
•
컨테이너 기반 인프라 관리
◦
통합 관리: Frontend, Backend, DB(PostgreSQL), Cache(Redis), Nginx, Monitoring Stack 등 모든 애플리케이션 및 인프라 구성 요소를 단일 EC2 인스턴스 내부에서 Docker 컨테이너로 실행합니다.
◦
환경 일관성: Docker Compose를 통해 서비스 간 의존성과 네트워크,볼륨,환경 변수를 통합 관리하며, 배포 환경에 구애받지 않는 실행 일관성을 유지하고 배포 및 재기동 시 빠른 복구가 가능합니다.
◦
내부 통신: 모든 서비스간 통신은 Docker Bridge Network 내부에서 컨테이너 이름을 기반으로 통신하여 서비스 디스커버리를 보장하고 네트워크 안정성을 높였습니다.
•
트래픽 라우팅 및 보안
◦
전용 도메인을 통한 서비스 접근: 외부 사용자는 EC2 인스턴스의 공인 IP가 아닌 구매한 도메인 URL을 통해 서비스에 접근한다.
◦
Nginx 리버스 프록시: 모든 요청은 Nginx 컨테이너를 거쳐 요청 경로에 따라 Frontend와 Backend로 트래픽을 라우팅합니다.
◦
전송 구간 암호화: Let’s Encrypt 인증서를 통한 HTTPS 통신을 제공하여 사용자의 데이터 전송 보안을 강화했습니다.
•
데이터 저장 및 성능 최적화
◦
Backend 서비스는 Redis와 PostgreSQL 컨테이너에 직접 접근하여 데이터를 처리한다.
◦
PostgreSQL: 서비스의 핵심 데이터를 안전하게 영구 저장합니다.
◦
Redis 캐시 계층: 인메모리 캐시 계층으로 사용되며 자주 조회되는 API 응답을 저장함으로써 데이터베이스 부하를 감소시키고 응답 속도를 개선했습니다.
•
중앙 집중형 모니터링
◦
로그 수집 및 분석: Alloy가 수집한 로그를 Loki로 전달하고, 이를 Grafana를 통해 실시간 모니터링 및 장애분석을 지원합니다.
◦
장애 대응: 실시간 모니터링 체계를 통해 운영 중 발생하는 장애를 빠르게 탐지하고, 원인을 분석하여 서비스의 지속적인 개선이 가능하도록 설계했습니다.
7-2. CI/CD PipeLine
본 프로젝트는 GitHub Actions와 Docker Hub를 활용하여 코드 통합부터 AWS 배포까지 전 과정을 자동화하였습니다. 모든 서비스는 컨테이너 기반으로 배포되며, 민감 정보는 GitHub Secrets를 통해 안전하게 관리됩니다.
전체 흐름 요약
1.
Push: 개발자가 GitHub prod 브랜치에 소스코드 푸시
2.
Trigger: GitHub Actions 워크플로우 감지 및 Trigger 실행
3.
CI (Test & Build): 백엔드 테스트 및 프론트/백엔드 Docker 이미지 빌드
4.
Push: 빌드된 이미지를 Docker Hub에 푸시
5.
CD (Deploy): AWS 서버 SSH 접속 후 배포 스크립트 실행을 통한 컨테이너 재기동
단계별 상세 작업 (Workflow)
Step 1. 테스트 단계 (CI)
•
Trigger: Pull Request 이벤트 또는 dev, prod 브랜치에 대한 Push 이벤트 발생 시
•
작업 흐름
1.
GitHub Actions 실행 환경 구성 및 Java 버전 설정
2.
백엔드 소스코드 단위 테스트 실행
3.
테스트 실패 시 상세 리포트 생성 및 피드백
a.
리포트 기반으로 실패 케이스 확인
Step 2. 빌드 및 이미지 푸시 (CI)
•
Trigger: prod 브랜치에 Push 이벤트 발생 시
•
작업 흐름
1.
GitHub Actions 실행 환경 구성
•
GitHub Secrets 및 Actions 환경변수 로드
•
Docker Hub 계정 정보, AWS 접속 정보 등 민감 정보는 Secrets로 관리 함
2.
FrontEnd 이미지 빌드 및 푸시
•
FrontEnd 소스 디렉토리를 기준으로 Dockerfile 기반 이미지 빌드
•
태그 정의서에 따라 이미지 태깅
•
Docker Hub 레지스트리에 이미지 푸시
3.
BackEnd 이미지 빌드 및 푸시
•
BackEnd 소스 디렉토리를 기준으로 Dockerfile 기반 이미지 빌드
•
동일한 방식으로 태깅 및 Docker Hub에 푸시
이 단계에서 CI의 책임은 “소스 코드 → 실행 가능한 컨테이너 이미지” 변환까지이며, 실제 서비스 반영은 수행하지 않는다.
Step 3. 배포 단계 (CD)
•
Trigger: Step 2의 이미지 푸시 작업 완료 이벤트 발생 시 (동일 워크플로우 내 후속 Job으로 구성)
•
작업 흐름
1.
AWS 서버 원격 접속
•
GitHub Actions에서 SSH 키 사용하여 AWS EC2 인스턴스 접속
•
서버 접근 권한은 배포 전용 계정으로 제한함
2.
배포 관련 파일 준비
•
docker-compose.yml
•
배포 프로필 파일
•
배포용 bash 스크립트
각 파일들은 서버에 직접 복사하거나, 이미 서버에 존재하는 파일을 기준으로 실행
3.
배포 스크립트 실행
•
bash 스크립트를 통해 아래 작업 순차적으로 수행
◦
Docker Hub에서 최신 이미지 pull
◦
기존 컨테이너 중지
◦
docker-compose 기반 컨테이너 재기동
•
서비스 중단 시간을 최소화하는 방식으로 컨테이너를 교체
7-3. 구현전략

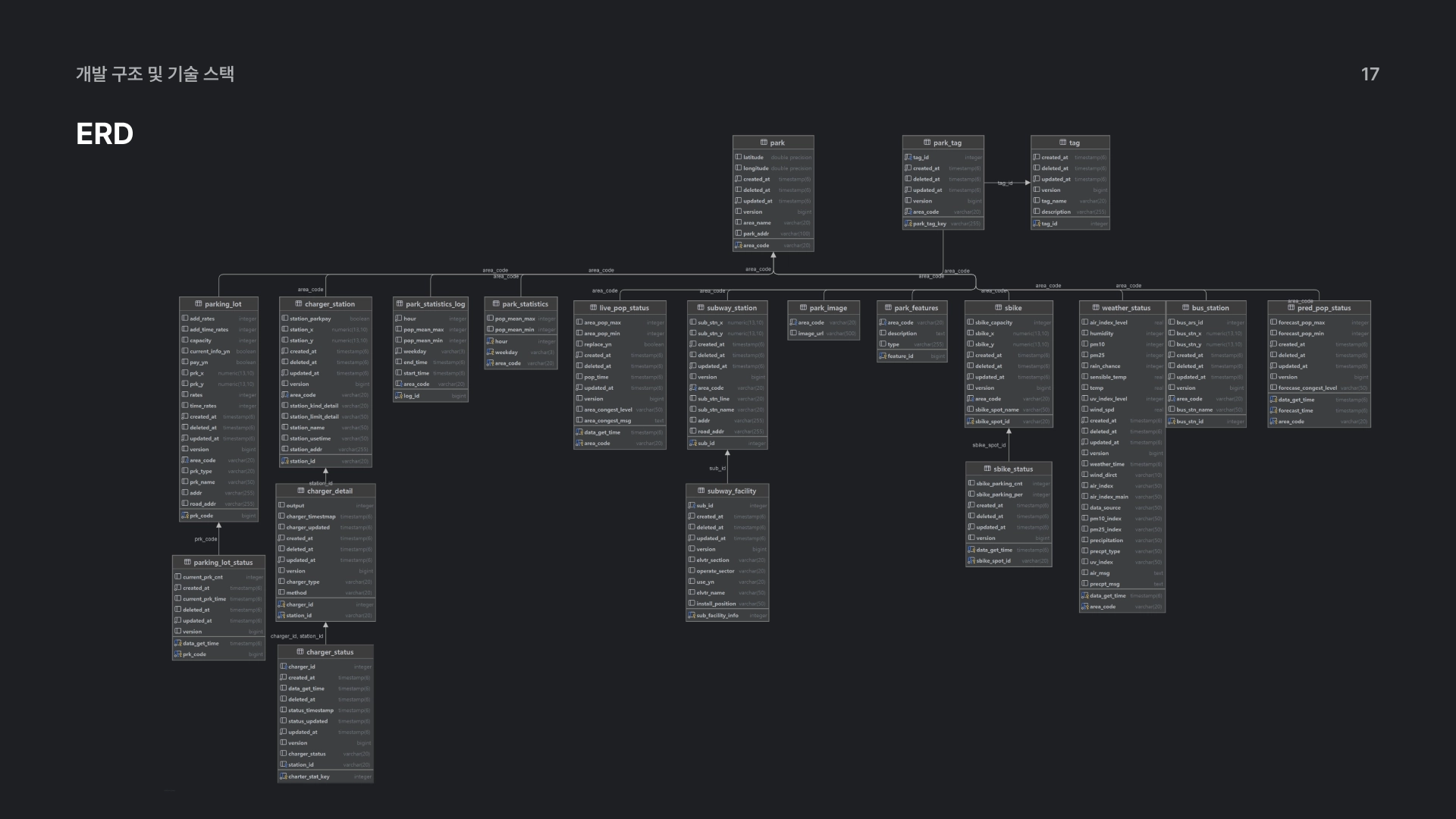
8. ERD
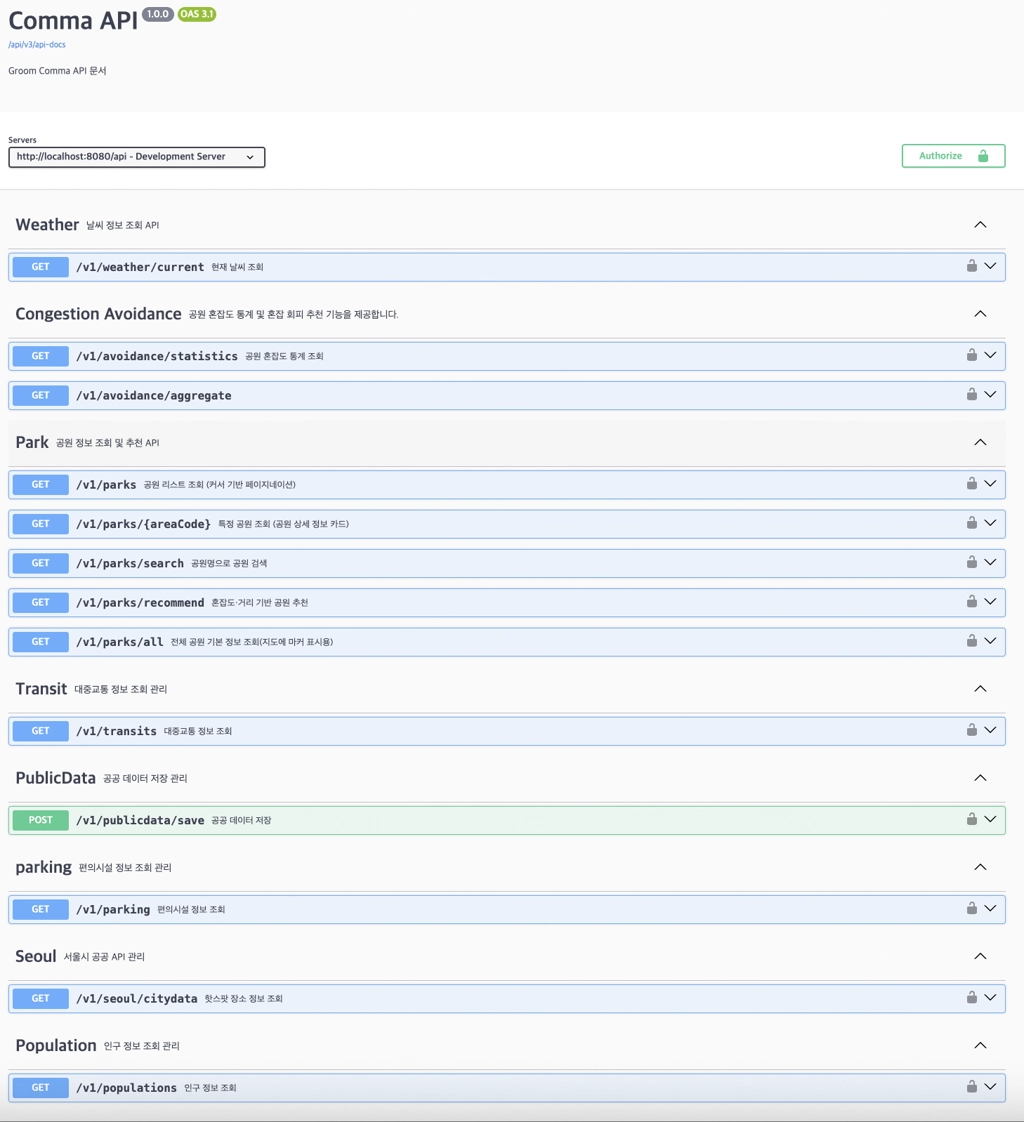
9. API활용 라이브러리 및 개발 환경
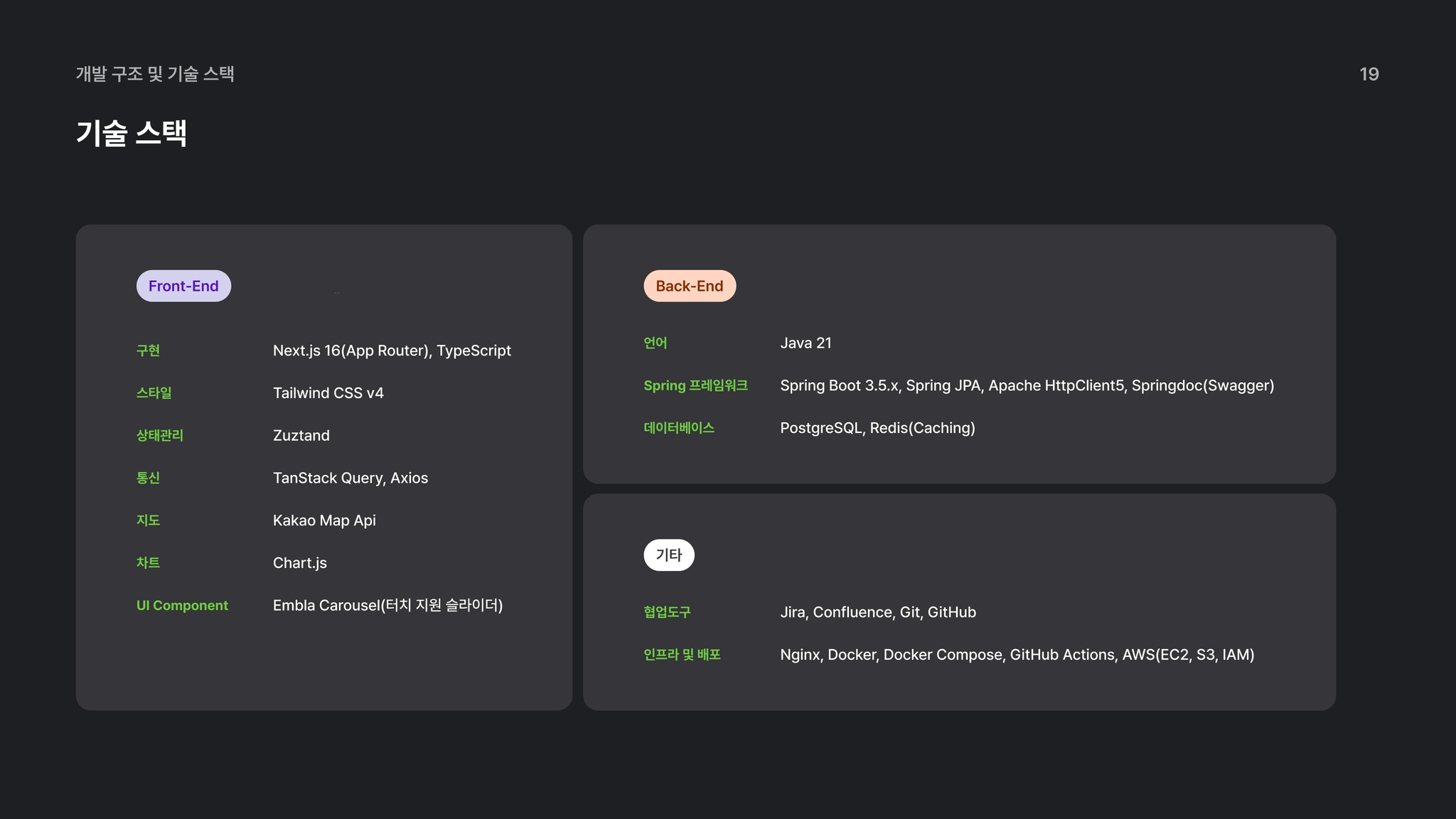
10. 기술스택
11. 주요 컴포넌트
역할 구분 | 구현 위치 | 주요 책임 | 특징 |
API Server | application/, domain/ 패키지의 Controller/Service | • RESTful API 엔드포인트 제공
• 비즈니스 로직 처리
• 데이터 조회 및 변경 작업 | • Stateless 설계로 수평 확장 가능
• 약 10개의 Controller로 도메인별 API 제공
• Spring Web MVC 기반 |
Batch Server | domain/publicdata/scheduler/application/avoidance/scheduler/ | • 주기적인 데이터 동기화
• 대용량 데이터 처리
• 통계 집계 작업 | • @Scheduled 기반 스케줄링• Spring Scheduler 활용
• API 요청 처리와 독립적으로 백그라운드 실행 |
12. 트러블 슈팅
FrontEnd
1. 환경 변수 경로 설정 오류로 인한 외부 API 연동 실패
•
문제 정의 (Problem) :브라우저를 통해 획득한 현재 위치(위도/경도)를 Kakao API를 사용하여 지역 이름으로 변환하는 로직 구현 중 500 Internal Server Error가 발생하였습니다. 정확한 에러 원인이 로그에 즉각적으로 나타나지 않아 서비스의 핵심 기능인 위치 기반 추천이 중단되는 상황이었습니다.
•
해결책 : .env 파일의 위치를 Next.js 작업 환경과 의존성 모듈이 포함된 goorm-comma/frontend/ 디렉토리로 이동 배치하였습니다. 위치 변경 후 프레임워크가 환경 변수를 정상적으로 인식하는지 확인하고, API Key를 활용한 Kakao API 통신 상태를 재점검하였습니다.
•
결과 : 정상적으로 환경 변수를 읽어오게 되면서 Kakao API를 통한 주소 변환 및 위치 기반 서비스가 정상 복구되었습니다.
BackEnd
1. Redis JSON 역직렬화 이슈
•
문제 정의: 기본 CacheManager 사용 시 캐시 값이 JSON으로 직렬화되나, 역직렬화 과정에서 구체적인 클래스 타입 정보를 알 수 없어 Jackson MismatchedInputException이 발생했습니다. 다중 도메인 환경에서 이 문제가 빈번히 발생할 가능성을 확인했습니다.
•
해결책: 도메인별로 명확한 직렬화/역직렬화 전략을 수립했습니다. 각 도메인에 대응하는 CacheManager를 개별 Bean으로 등록하고, 적절한 RedisSerializer를 명시적으로 설정했습니다.
•
결과: 역직렬화 오류가 제거되었으며, 도메인별 캐시 책임 분리로 설정의 가독성과 유지보수성이 향상되었습니다.
2. EnableJpaAuditing 관련 JUnit 테스트 이슈
•
문제 정의: @EnableJpaAuditing이 메인 클래스에 선언되어 있어, JUnit 유닛 테스트 시에도 JPA Auditing이 활성화되었습니다. 이로 인해 JPA를 사용하지 않는 단위 테스트에서도 DB 연결 오류가 발생했습니다.
•
해결책: JPA Auditing 설정을 애플리케이션 전역 설정에서 분리했습니다. 별도의 @Configuration 클래스를 생성하여 어노테이션을 이동시키고, 테스트 환경에서는 해당 클래스가 로딩되지 않도록 구성했습니다.
•
결과: 유닛 테스트에서 불필요한 의존성이 제거되었고, 실행 환경과 테스트 환경의 설정 책임이 명확히 분리되었습니다.
3. 혼잡 시간 예측 모델의 구조적 설계
•
문제 정의: 휴리스틱 기반의 예측 로직이 요구사항 변경에 따라 복잡도가 빠르게 증가하여 향후 큰 개발 부채가 될 위험이 있었습니다.
•
해결책: 기존 모델을 유지하되, 예측 로직을 인터페이스 기반으로 추상화했습니다. 내부 구현을 언제든 교체할 수 있도록 설계하여 향후 ML 기반 모델이나 고도화된 통계 모델로 대체 가능한 구조를 마련했습니다.
•
결과: 구조적 부채 확산을 제어하고, 향후 모델 고도화 시 발생할 리팩토링 비용을 예측 가능한 수준으로 제한할 수 있는 기반을 확보했습니다.
4. Redis 데이터 최신성 및 Race Condition 문제
•
문제 정의: 매 정각 데이터 갱신 시점에 캐시 삭제 및 업데이트가 동시에 발생할 경우, 다중 요청 환경에서 Race Condition이 발생할 가능성이 존재했습니다. 이로 인해 오래된 데이터 반환이나 불필요한 캐시 미스가 우려되었습니다.
•
해결책: 캐시 키에 시간 정보를 포함시켜 데이터 최신성을 키 구조 자체로 판단하도록 변경했습니다. 또한 TTL(Time To Live)을 60분으로 설정하여 경과된 데이터가 자동 만료되도록 구성했습니다.
•
결과: Race Condition 문제를 근본적으로 제거했으며, 명시적인 캐시 무효화 로직 없이도 데이터 최신성을 보장하는 단순하고 견고한 구조를 구축했습니다.
BackEnd
1. 로그 수집 및 조회 최적화
•
문제 정의: 초기 구축 단계에서 Backend 로그가 Grafana에 표시되지 않는 수집 결함이 발생했습니다. 또한, 시스템 정상화 이후 로그량 증가로 인해 특정 API 호출 로그를 신속하게 탐색하기 어려운 환경이었습니다.
•
해결책: * 인프라 레벨 개선: 로그 공유 구조를 표준화하고 서비스 실행 순서를 재정립하여 수집 안정성을 확보했습니다. 환경별 설정 일관성을 유지하고 접근 권한을 정비하여 오류를 제거했습니다.
◦
조회 방식 개선: 시간 범위를 세분화하고 키워드 및 조건 기반 필터링을 도입했습니다. 실시간 로그 조회 기능을 통해 API 호출 즉시 로그를 확인할 수 있는 운영 프로세스를 마련했습니다.
•
결과: 모니터링 시스템의 신뢰도가 향상되었으며, 대량 로그 환경에서도 특정 이벤트를 빠르게 추적할 수 있게 되어 장애 분석 및 운영 효율이 전반적으로 향상되었습니다.
2. 스케줄러 오류 처리 및 트랜잭션 관리
•
문제 정의: 30분 주기의 공공 데이터 업데이트(PublicDataScheduler) 과정에서 단일 공원의 데이터 저장 실패가 전체 작업의 롤백이나 중단으로 이어지는 구조였습니다. 이로 인해 성공한 데이터까지 손실되는 안정성 문제가 발생했습니다.
•
해결책: * 트랜잭션 분리: 개별 공원별로 try-catch 블록을 적용하여 부분 실패가 전체 작업에 영향을 주지 않도록 구현했습니다.
◦
상세 로깅 시스템: 실패한 공원명과 사유를 별도 리스트로 추적하여 상세 로그를 출력함으로써 즉각적인 장애 파악이 가능하도록 했습니다.
◦
데이터 일관성 확보: 분 단위 정규화(normalizeToMinute)를 통해 중복 저장을 방지하고 데이터의 신뢰성을 높였습니다.
•
결과: 일부 데이터 실패에도 전체 작업이 중단되지 않아 데이터 손실이 최소화되었으며, 스케줄러의 안정성과 신뢰성이 크게 강화되었습니다.
3. 공원 리스트 조회 N+1 쿼리 문제 해결
•
문제 정의: 필터링 및 정렬 기능을 통합하는 과정에서 공원 1곳 조회 시 날씨, 인구, 태그 정보를 각각 호출하는 N+1 문제가 발생했습니다. 공원이 30개일 경우 총 91번의 쿼리가 실행되어 응답 시간이 수십 초까지 지연되는 심각한 성능 저하가 나타났습니다.
•
해결책: * 배치 조회(Batch Query) 도입: 모든 areaCode를 한 번에 수집한 후 각 도메인별로 배치 조회를 수행하도록 로직을 변경했습니다.
◦
Repository 레이어 고도화: findLatestByAreaCodes() 및 JOIN FETCH를 활용한 태그 정보 일괄 조회를 통해 추가 쿼리 발생을 원천 차단했습니다.
◦
메모리 기반 매핑: 가져온 데이터를 Map 형태로 메모리에 로딩하여 순회함으로써 쿼리 수를 공원 수와 무관하게 일정하게 유지했습니다.
•
결과: 기존 91번의 쿼리를 단 4번으로 감소시켜 응답 시간을 수십 초에서 수백 밀리초로 단축했습니다. 공원 수 증가에도 성능이 일정하게 유지되는 확장 가능한 기반을 마련했습니다.