

배경(Problem)
여행지에서의 ‘결정의 어려움’은 특정 그룹에게 더 큰 장벽으로 다가옵니다. 현재 대부분의 여행 추천 서비스는 디지털에 익숙한 젊은 세대를 중심으로 설계되어, 두 그룹을 소외시키고 있습니다.
1. 시니어 세대
디지털 기기 사용에 익숙하지 않은 어르신 세대는 여행 정보를 얻는 과정에서 큰 피로감을 느낍니다.
•
최신 정보 부족 및 모바일 검색의 불편함: 복잡한 메뉴와 수많은 필터 앞에서 새로운 도전을 포기하고, 결국 늘 방문하던 익숙한 곳만 찾게 됩니다.
•
디지털 소외: 정보의 홍수 속에서 오히려 갈 곳을 잃고, 기술 발전이 여행의 설렘보다 불편함을 먼저 느끼게 하는 장벽이 되고 있습니다.
2. 외국인 여행객: 정제되지 않은 정보 과부하와 단절
외국인 여행객은 수많은 정보 속에서 자신에게 맞는 정보를 찾지 못할 뿐만 아니라, 그들만의 정보 공유 방식에서 또 다른 문제를 겪고 있습니다.
•
정보의 비대칭성: 진짜 맛집, 명소 등 유용한 정보는 특정 국가 출신 커뮤니티 내에서만 구두로 공유되는 ‘그들만의 리그'가 형성되어 있습니다.
•
플랫폼의 부재: 기존 플랫폼은 철저히 한국인 중심으로 설계되어 외국인에게는 불필요한 정보가 많고, 문화적 차이를 고려한 그들의 경험을 공유할 공간이 절대적으로 부족합니다.
•
이중 소외 문제: 이로 인해 특정 커뮤니티에 속하지 못한 외국인은 대한민국이라는 타지에서 ‘외국인’이라는 집단에마저 속하지 못하는 ‘두 번의 외지인’이 되는 문제를 낳고 있습니다.
저희는 기술이 사람을 소외시키는 것이 아니라, 모두를 연결하는 다리가 되어야 한다고 생각했습니다.
이처럼 각기 다른 이유로 여행의 즐거움을 온전히 누리지 못하는 사람들의 ‘결정의 어려움’을 해결하는 것이 저희 프로젝트의 시작입니다.
서비스 소개(Solution)
아키텍처 및 핵심 기능
프로젝트 아키텍처



저희 아키텍처는 데이터의 사전 처리와 실시간 검색이라는 두 가지 핵심 단계로 구성됩니다. 이를 통해 방대한 정보를 효율적으로 관리하고, 사용자 질문에 가장 정확한 답변을 신속하게 제공합니다.
Phase 1: 데이터 준비 및 벡터화 (비동기 처리)
사용자 질문에 빠르고 정확하게 답변하기 위해, 데이터를 사전에 가공하여 검색 가능한 ‘지식 베이스’를 구축합니다.
1.
데이터 수집 및 저장
TourAPI 정보와 자체적으로 수집한 사용자 리뷰 데이터를 일반 데이터베이스에 저장합니다.
2.
핵심 리뷰 요약 생성
데이터베이스에 축적된 데이터를 기반으로, 각 장소의 핵심 특징과 평가를 담은 **‘리뷰 요약본’**을 생성합니다.
3.
비동기적 업데이트
특정 장소에 대한 리뷰가 일정량 쌓이면, 리뷰 요약 모델이 비동기적으로 작동하여 ‘리뷰 요약본’을 항상 최신 상태로 유지합니다.
4.
요약본 벡터화 및 저장
생성된 ‘리뷰 요약본’을 KoSBERT 임베딩 모델을 통해 벡터로 변환하고, 검색에 최적화된 Pinecone 벡터 DB에 저장합니다.
Phase 2: 실시간 사용자 요청 처리 (RAG 파이프라인)
사용자의 질문이 들어왔을 때, 가장 관련성 높은 정보를 찾아내고 LLM을 통해 최적의 답변을 생성하는 과정입니다.
1.
사용자 질문 벡터화
사용자의 질문을 KoSBERT 모델을 통해 벡터로 변환합니다. (※ 비한국어 질문은 m2m-100 모델로 번역 후 진행)
2.
1차 시맨틱 검색 (Recall)
질문 벡터와 의미적으로 가장 유사한 ‘요약본 벡터’ 여러 개를 Pinecone 벡터 DB에서 신속하게 검색합니다.
3.
원본 데이터 로딩 (Enrichment)
검색된 요약본과 연결된 모든 원본 데이터(개별 리뷰 전체, 관련 TourAPI 정보 등)를 일반 DB에서 불러와 컨텍스트를 풍부하게 구성합니다.
4.
Agentic Rerank & 답변 생성 (Synthesis)
최종적으로 [사용자 질문] + [검색된 요약본] + [불러온 원본 데이터 전체]를 LLM에 전달합니다. LLM은 이 모든 정보를 종합적으로 판단하여, 가장 정확하고 적절한 답변을 생성하고 최종 순위를 결정(Rerank)합니다.
시퀀스 다이어그램

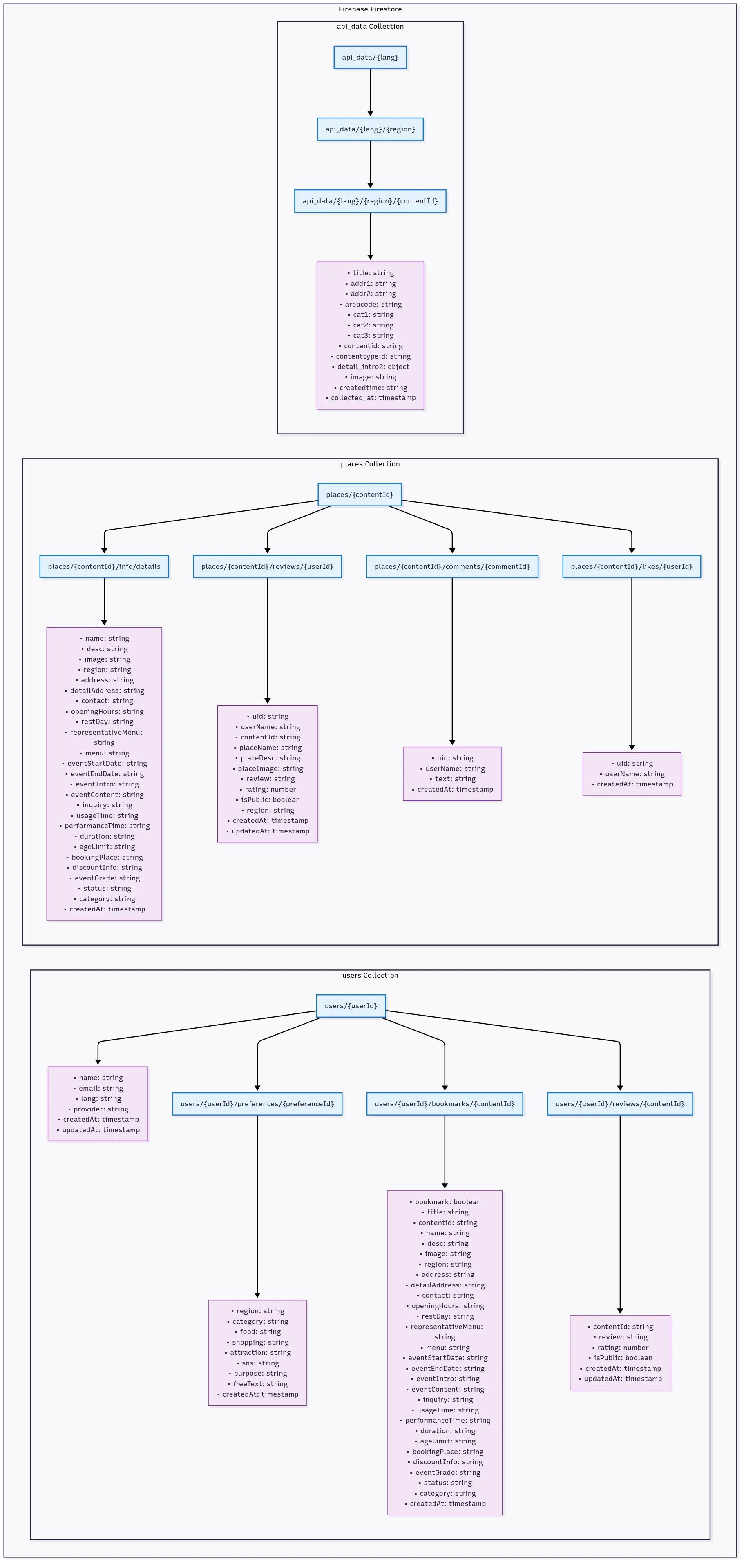
firebase database 구조
활용 라이브러리 및 개발 환경
기술스택
Frontend (클라이언트)
•
Vue.js 3.5.17 - 메인 프레임워크
•
Vite 7.0.5 - 빌드 도구 및 개발 서버
•
Vue Router 4.5.1 - SPA 라우팅
•
Firebase SDK 11.10.0 - 인증 및 실시간 데이터베이스
Backend (서버)
•
FastAPI
•
Python 3.8
•
Firebase Admin SDK - 서버사이드 Firebase 연동
•
Uvicorn - ASGI 서버
Database & Authentication
•
Firebase Firestore - NoSQL 실시간 데이터베이스
•
Firebase Authentication - 사용자 인증 시스템
트러블 슈팅
 M2M100-1.2B 모델은 범용 번역 성능은 우수했지만, 저희 'SOYO' 서비스에 바로 적용하기에는 명확한 한계가 존재했습니다. 이를 해결하기 위해 총 2단계에 걸친 파인튜닝 및 검증을 진행했습니다.
M2M100-1.2B 모델은 범용 번역 성능은 우수했지만, 저희 'SOYO' 서비스에 바로 적용하기에는 명확한 한계가 존재했습니다. 이를 해결하기 위해 총 2단계에 걸친 파인튜닝 및 검증을 진행했습니다.1. 문제 정의: 기본 모델의 치명적 약점, '고유 명사'
가장 큰 문제는 ‘한국 특유의 고유 명사’ 번역 오류였습니다. ‘경복궁’이나 ‘설빙’ 같은 고유 명사를 전혀 다른 품사(동사, 형용사 등)로 잘못 번역하여, 문장 전체의 구조와 의미를 파괴하는 심각한 문제를 확인했습니다.
서비스의 핵심인 장소 및 브랜드 이름의 정확한 전달을 위해, 파인튜닝은 선택이 아닌 필수였습니다.
2. 1차 파인튜닝: 최적의 학습 방법론 탐색
•
A/B 테스트: Full-Tuning(전체 파라미터 학습) 방식과 LoRA(경량화 튜닝) 방식을 비교 실험했습니다.
•
엄격한 검증: 평가의 신뢰도를 높이기 위해 자동 평가 지표(XCOMET)와 정성 평가(LLM-as-a-Judge)를 병행했습니다.
•
결과 및 결정
◦
1.5 Epoch Full-Tuning 모델이 XCOMET 점수에서 가장 높은 성능을 기록했습니다.
◦
전반적으로 Full-Tuning이 LoRA 방식보다 우수한 결과를 보여, 이를 기반 모델로 채택하고 LoRA 접근법은 폐기했습니다. LoRA방식을 더했음에도 성능이 낮아진 것을 보며 평가지표의 필요성을 크게 느꼈습니다.
3. 2차 파인튜닝: 핵심 언어 성능 극대화 및 최종 모델 확정
1차 평가에서 발견된 문제를 해결하고 핵심 타겟 언어의 성능을 극대화하기 위해 추가 학습을 진행했습니다.
•
선택과 집중: 이전 단계에서 가장 성능이 좋았던 모델을 기반으로, 주요 타겟 언어인 중국어와 일본어 문장만을 100% 사용하여 추가 학습을 진행했습니다.
•
과적합 방지: 학습 과정에서 과적합 징후가 나타나는 최적의 지점에서 학습을 조기 종료(Early Stopping)하여 성능 저하 없이 모델을 완성했습니다.
•
최종 모델: 이 과정을 통해 최종 모델인 m2m100-finetuned-ko-ja-zh 를 성공적으로 개발했습니다.
추가 실험 및 교훈
2차 파인튜닝 과정에서 발생할 수 있는 영어 성능 저하를 막기 위해 전체 데이터셋을 다시 학습시키는 추가 실험도 병행했습니다. 하지만 여러 언어가 뒤섞여 번역되는 등 심각한 과적합 현상이 발견되어 해당 접근법은 폐기했습니다. 이는 정량평가에서는 발견되지 않았던 오류입니다. 정성평가를 소홀히 하고있었는데 정성평가의 중요성을 깨닫게 되었습니다.
블로그 리뷰 데이터를 분석해 각 여행 장소를 대표하는 매력적인 한마디 키워드를 추출합니다. 키워드만으로 사용자가 이 장소를 추천받은 이유(경험·느낌·설명)를 명확히 가시화하고, 추천 성능 개선에 기여하는 것이 핵심 목표입니다.1.
초기 문제점 인식: 프로젝트 초기에는 순수하게 블로그 리뷰 텍스트를 기반으로 키워드를 분류했습니다. 하지만 이 방법은 한계가 명확했습니다. 예를 들어, 특정 해수욕장에 대한 리뷰에 '바다'라는 키워드가 없으면, 해당 장소의 '바다/산'이라는 토픽으로 정확히 분류되지 않는 문제가 발생했습니다. 즉, 텍스트 데이터의 존재 여부에 크게 의존해 분류 정확도가 떨어졌습니다.
2.
TourAPI 카테고리 통합: 이 문제를 해결하기 위해, 한국관광공사가 제공하는 TourAPI의 '콘텐츠 카테고리(cat1, cat2, cat3)' 정보를 활용하는 전략을 도입했습니다. 이 카테고리 코드는 관광지를 '역사관광지', '휴양관광지', '자연관광지' 등으로 객관적으로 분류해놓은 공식적인 데이터입니다.
3.
LDA-카테고리 통합 분류 시스템: 저희는 LDA 토픽 분석으로 발견한 패턴('사찰 체험', '자연 힐링')과 TourAPI의 카테고리 코드를 결합하여 새로운 분류 시스템을 구축했습니다.
•
1단계: 우선적으로는 TourAPI의 카테고리 코드를 기반으로 관광지를 분류했습니다. 이는 가장 객관적이고 정확한 기준이 됩니다.
•
2단계: 카테고리 정보가 없는 경우나, 더 세부적인 키워드를 추출해야 할 때는 LDA 분석에서 얻은 토픽별 키워드 패턴을 적용했습니다.
이러한 하이브리드(Hybrid) 접근법을 통해 단순히 텍스트에 의존하던 기존의 한계를 극복하고, 관광지의 성격을 훨씬 더 정확하게 파악할 수 있게 되었습니다.
최종 결과 및 교훈
TourAPI 카테고리 활용은 단순히 키워드 추출을 넘어, 관광지 자체의 본질을 파악하는 데 결정적인 역할을 했습니다. 이 덕분에 '바다' 키워드가 없더라도 TourAPI 카테고리 코드가 '해수욕장'을 의미하면 '바다/산'으로 정확하게 분류할 수 있었고, LDA를 통해 '해수욕장'에서 발견되는 '일출 바다' 같은 매력적인 키워드까지 효과적으로 추출할 수 있었습니다. 이를 통해 텍스트 분석의 한계를 공공데이터로 보완하여 최종적인 키워드 시스템의 품질을 향상시켰습니다.