

배경(Problem)
•
현황
◦
논문에 접근하는 데 대중들 불편함이 존재
◦
논문을 주로 이용하는 연구자 및 학생 등의 불편감 호소
◦
검색에만 의존하는 기존 논문 사이트
•
논문 대중화를 통한 논문에 대한 접근성 향상
◦
접근성 : 사용자가 학술 자료에 쉽게 접근할 수 있도록 함으로써, 학문적 배경이 다양한 이들도 필요한 논문을 손쉽게 찾을 수 있게 합니다.
◦
편리성 : 사용자 친화적 인터페이스와 맟춤형 추천을 통해 사용자가 최소한의 노력으로 필요한 정보를 효율적으로 얻을 수 있도록 지원합니다.
◦
시의성 : 최신 뉴스 기반의 논문을 추천함으로써 사용자가 현재 중요한 주제에 대한 최신 정보를 신속하게 접할 수 있게 합니다.
서비스 소개(Solution)
•
논문 추천 서비스
•
논문 검색 서비스
아키텍처 및 핵심 기능
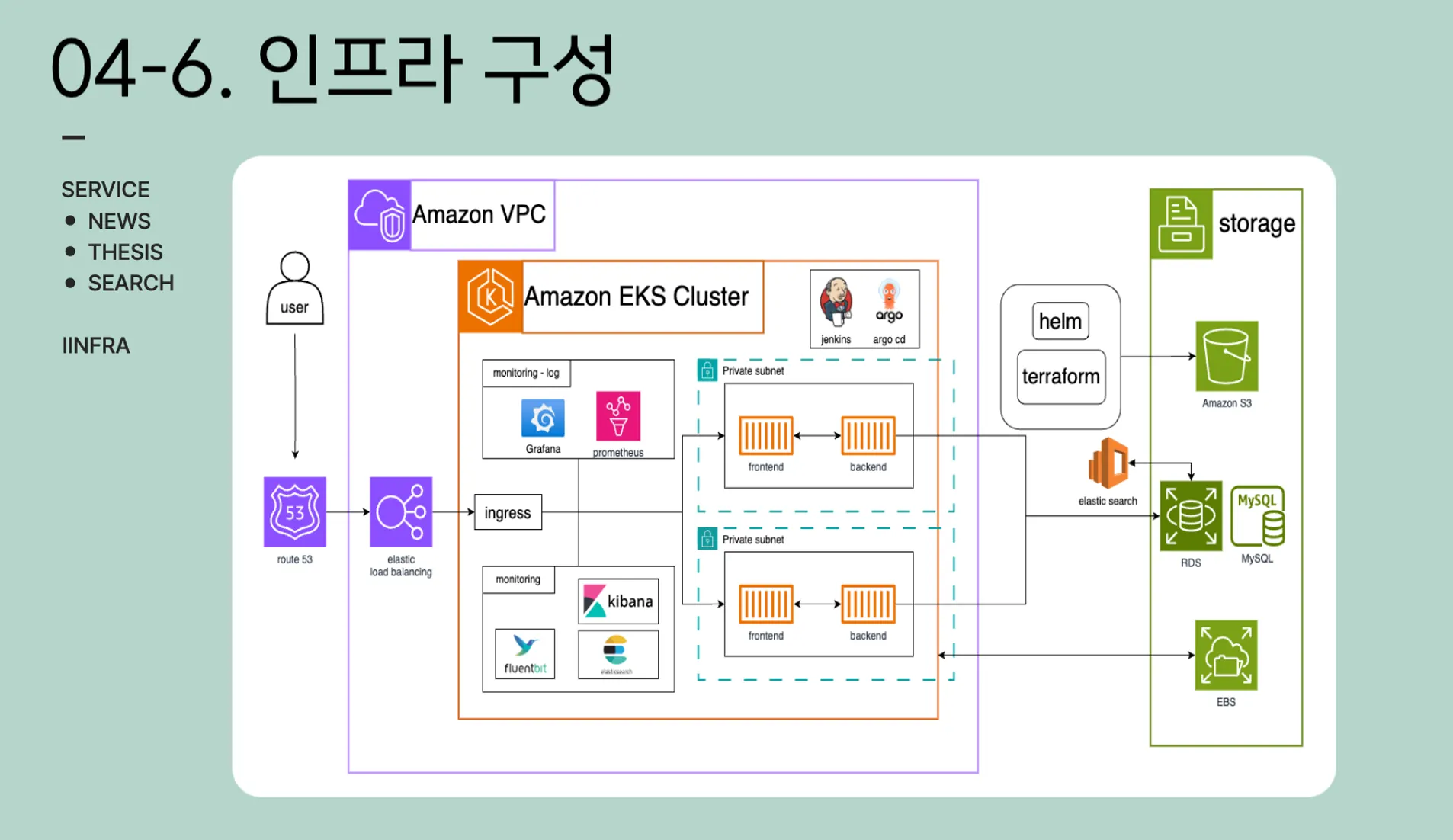
 기본적인 인프라 구성입니다
기본적인 인프라 구성입니다•
Terraform으로 versioning을 위해 두개의 클러스터로 구별하였습니다.
•
ingress와 elb를 사용하여 유저가 서비스를 이용하도록 설정하였습니다
•
AWS의 RDS를 사용하여 database는 외부의 환경으로 분리하였습니다.
•
추후 버전 관리를 위해 terraform과 helm chart는 S3에 저장하여 공유하였습니다.
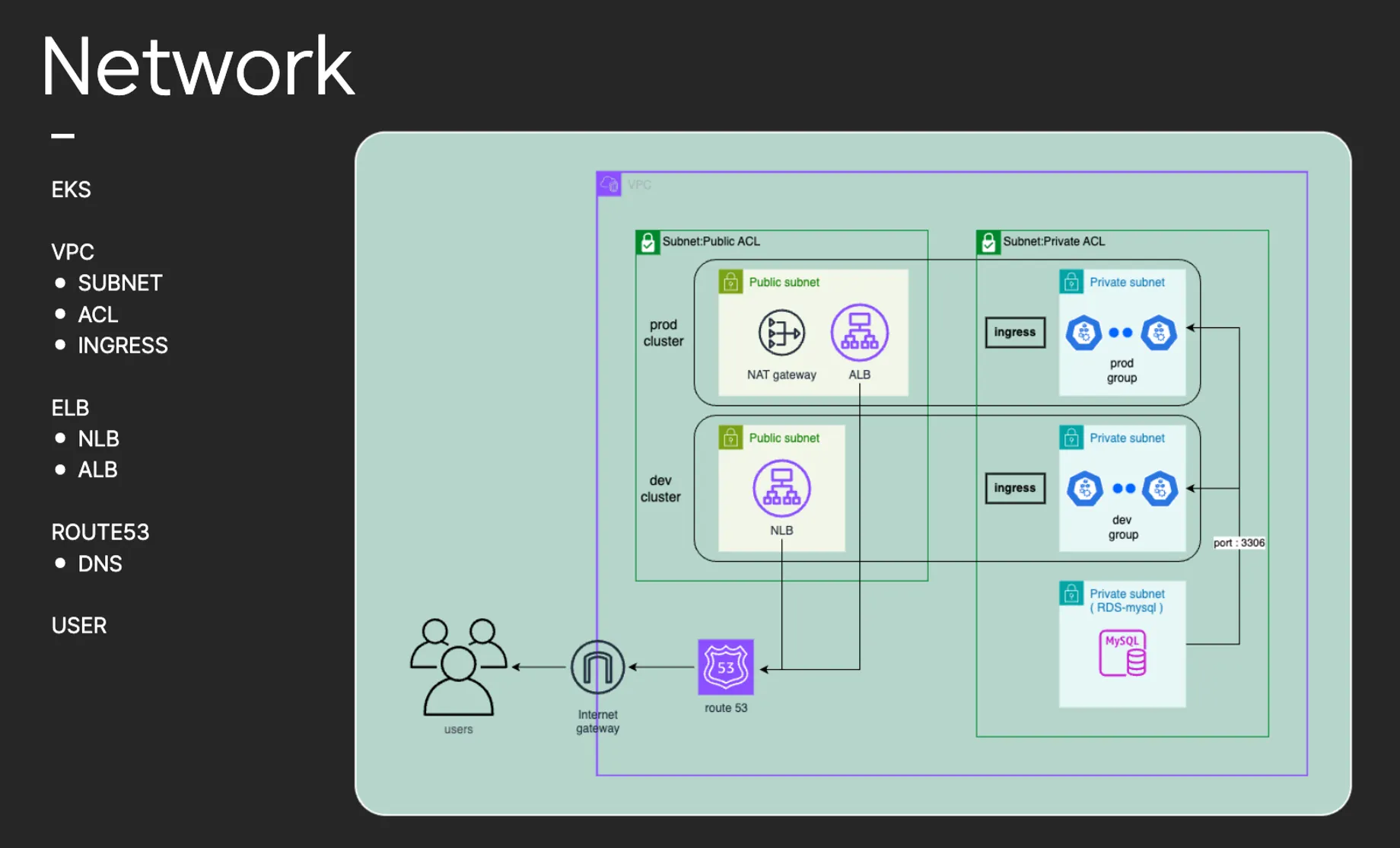 네트워크 구성입니다.
네트워크 구성입니다.•
보안을 고려하여 퍼블릭과 프라이빗 서브넷의 ACL을 분리하였습니다.
•
각각의 ALB와 NLB를 구성하여 사용자가 접근할 수 있게 만들어 주었습니다.
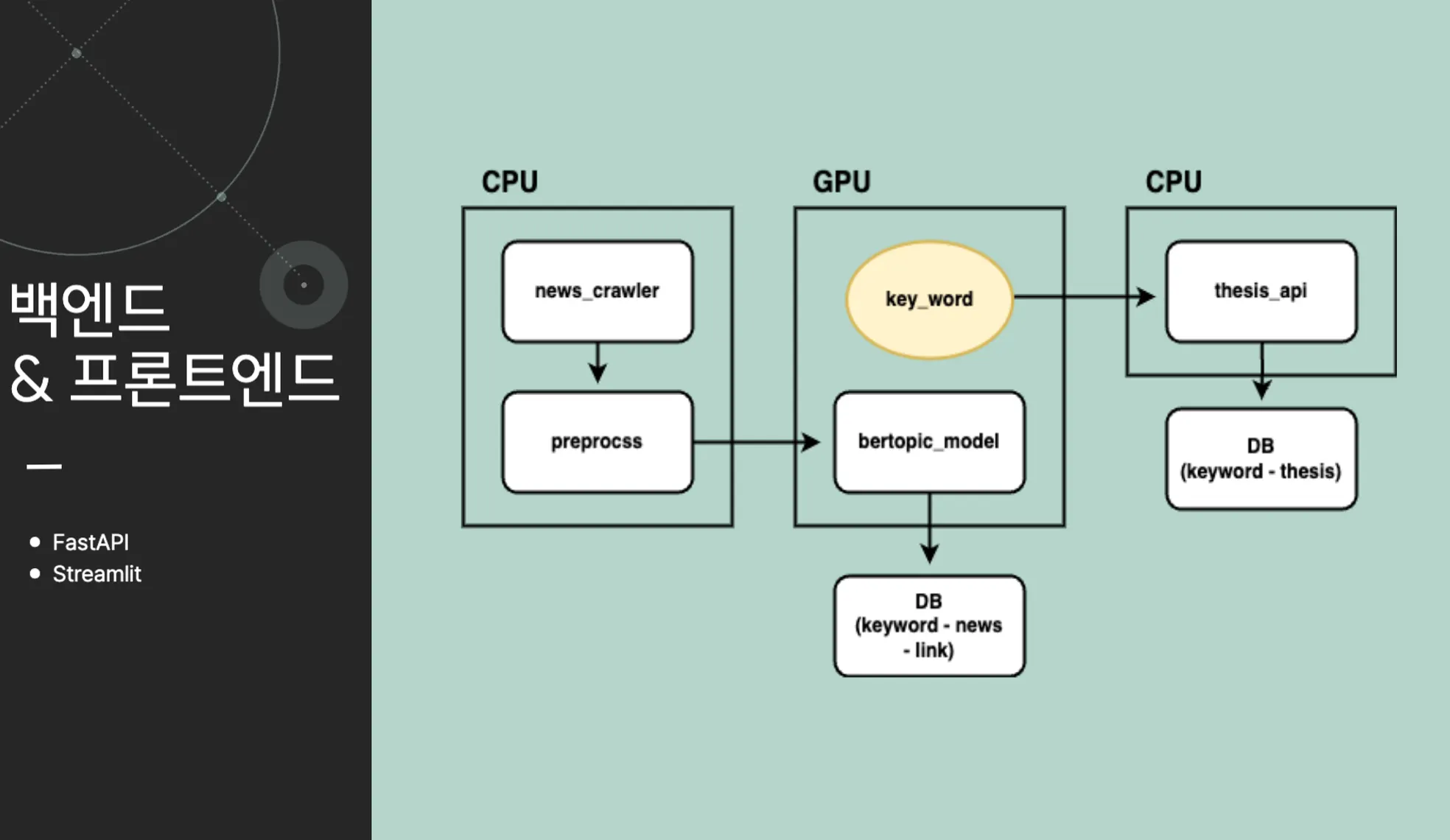 서비스 구현 모형입니다
서비스 구현 모형입니다•
모든 백엔드 모델들은 fastapi 로 구성하였습니다.
•
뉴스 크롤러가 오후 정시 00:00에 이전 뉴스를 크롤링합니다.
•
이후 크롤링된 데이터를 전처리 실시 후, 토픽 추출 모델에 데이터를 전달합니다
•
전달 된 데이터를 기반으로 키워드를 추출한뒤, 키워드-뉴스 형식으로 DB에 저장합니다.
•
추출된 키워드를 바탕으로 검색된 논문들을 DB에 저장합니다.
•
streamlit으로 구성된 프론트 환경에서는 DB에 저장된 뉴스와 키워드를 기반으로 하는 정보들을 유저에게 제공합니다. 또한 검색엔진을 논문 검색 api와 연동하여 유저가 사용할 수 있게끔 만들어 주었습니다.
활용 라이브러리 및 개발 환경
•
모델링 - python
◦
기본적인 내부 모델들은 python 언어를 사용했습니다.
◦
개발 환경은 각자의 os환경에 맞도록 개발하였고 colab을 사용하여 모델링을 실시하였습니다.
•
frontend - streamlit
◦
python 기반의 프론트 웹 구성입니다. 코드 몇줄로 하여금 웹을 간단하게 구연할 수 있습니다.
◦
이후 dockerization 을 통해 pod을 구성하였습니다.
•
backend - fastapi
◦
python 기반의 백엔드 구성입니다. flask와 달리 async를 사용할 수 있어 동시 처리를 위해 채택하였습니다.
◦
이후 dockerization 을 통해 pod을 구성하였습니다.
•
k8s : 가장 많이 사용되는 stack 을 선정했습니다.
◦
monitoring(Log) - prometheus, grafana, alertmanager
◦
monitoring - efk (elasticsearch, fluentbit, kibana)
◦
CI/CD - jenkins, ArgoCD
◦
terraform, helm, redis, mysql on rds
•
load test - JMeter
트러블 슈팅
•
개발환경 일치
◦
프로젝트 하면서 가장 필요성을 느꼈던 부분입니다. 자연어처리 포지션과의 협업을 위해서는 필수적인 과정이라고 생각합니다.
◦
추후 k8s 환경에 배포를 생각한다면 dockerization이 필수입니다. 이 때, 모델의 버전이 일치되지 않으면 배포시 다양한 문제가 발생할 수 있습니다. colab 환경에서의 모델 개발보다는 개인 local 또는 공유된 가상환경에서의 작업을 추천합니다. python library의 버전은 꽤나 모듈끼리 충돌이 많은 것 같습니다.
•
비용문제
◦
제한된 resource 내에서 사용함에 따라, 저희는 모델 test 및 deploy 전에 먼저 local이나 각자 환경에서 연동 test를 진행하였습니다.
◦
이후 기본적인 model이 완성됨에 따라 EKS 환경으로 이동하여 테스트를 진행하였습니다.
◦
매일 리소스 체크는 필수인 것 같습니다.
•
helm chart 배포
◦
helm chart를 사용하여 tool을 사용하면 매우 편리합니다. 하지만 custom 해야할 부분이 반드시 존재합니다. 저희는 chatgpt를 이용하는 것보다 helm chart의 git에 들어가서 직접 custom value를 수정하여 사용하는 것을 추천드립니다.
◦
배포시 연결된 툴 사이의 버전을 고려하는 것도 문제를 줄이는 한 가지 방법입니다!
•
부하테스트
◦
저희가 사용한 streamlit 기반의 프론트엔드는 비동기식이라 JMeter를 사용하여 부하테스트 하는데 어려움이 많았습니다.
◦
저희는 직접 selenium을 사용한 webdriver를 JMeter와 연동하여 코드를 짜서 진행했는데 java 코드이다 보니 어려움이 많았습니다.
◦
그래서 web을 구성하실 때에는 react 나 vue.js 사용하시는 걸 추천드립니다. 저희는 프론트엔드 경험자의 부재로 streamlit으로 진행하였습니다.
팀 소개
논문의 대중화
정수호(팀장) (쿠버네티스 15회차) - suho8346@gmail.com
노지원(자연어처리 14회차)
여민수(자연어처리 14회차) - minsooyeo9004@gmail.com
이상윤(쿠버네티스 15회차) - leesy010504@gmail.com
임상규(쿠버네티스 15회차) - 0892668@gmail.com